
Pattern Analysis for Machine Olfaction: A Review
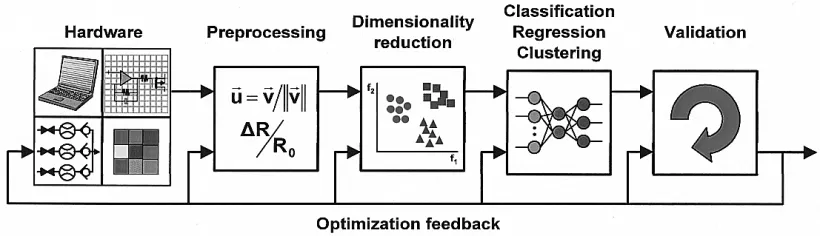
Pattern Analysis constitutes a critical building block in the development of gas sensor array instruments capable of detecting, identifying, and measuring volatile compounds, a technology proposed as an artificial substitute of human olfactory system. The multivariate response of an array of chemical gas sensors can be utilized as an ‘electronic fingerprint’ to characterize a wide range of odorsor volatile compounds. The process of analysis is largely split into four stages: signal pre-processing, dimensionality reduction, prediction and validation.
The process,after storing the sensor signals, starts with signal pre-processing. It involves compensating for sensor drift, extracting descriptive parameters from the sensor array response by using compression algorithms and preparing the feature vector for further processing by normalization.
The feature vector obtained from pre-processing stage suffers from high-dimensionality and redundancy. High dimensions beyond a point can lead to degradation. Feature extraction methods such as principal component analysis [PCA] and Fisher’s linear discrimination analysis [LDA] can be employed to find a low-dimensional mapping that preserves most of the information from the original feature vector. Feature subset selection focuses on to find an optimal subset of sensors that maximizes information content and predictive accuracy.
Next, classification tasks address the problem of identifying an unknown samplefrom a set of previously learned odorants. The K-nearest neighbours rule is a powerful technique that can be used to generate highly nonlinear classifications with limited data. Artificial neural networks such as Multilayer Perceptron Classifier, wherein each neuron in the network performs a weighted sum of its inputs and transforms it through a nonlinear activation function and Radial Basis Function Classifier are commonly in use.
Regression establishes predictive model from a set of independent variables (e.g.: gas sensor responses) to another set of continuous dependant variables. Pattern classification is therefore regression problem where dependant variable is categorical. Three basic regression techniques have been addressed with e-nose instruments namely multi-component analysis, process monitoring and sensory analysis. Mimicking the perception of odors by human is the ultimate challenge for machine olfaction. Ordinary Least Square technique, Ridge Regression, Partial Least Squares techniques are used interchangeably to obtain the best output of regression.
Clustering is an unsupervised learning process that seeks to find spatial relationships among data samples, which may be hard to discern in high-dimensional feature space. It consists of defining a dissimilarity measure between examples, defining a clustering criterion to be optimized and defining a search algorithm to find a good assignment of examples to cluster. Hierarchical clustering, Agglomerative, C-means are popular algorithms for clustering.
Appropriate model as well as perfect parameter settings is required for optimal performance. Training set is used to learn several models, and the training model that performs best on validation data is selected as final model. Holdout methods, K-fold cross validation, leave-one-out cross validation techniques are used for validation.
To conclude, the development of biologically plausible computational modelsof human olfactory perception and processing constitutes a grand challenge for the machine olfaction of the future.