
CNN-Based Classification for Point Cloud Object With Bearing Angle Image
The Advanced Driver Assistance System (ADAS) uses sensors and cameras to recognize and classify objects or obstacles. Traditionally, ADAS has used 2D images for object recognition, as they are cost-effective. However, images captured in irregular lighting often raise false alarms.
3D images produced by Light detection and ranging (LiDAR), which emits laser and then measures reflection time, are more accurate and reliable. LiDAR sensors generate point clouds, a massive collection of tiny data points plotted in 3-Dimentional space. Recently, there has been growing interest in Convolutional Neural Networks (CNNs) for segmenting and classifying point clouds in images captured by LiDAR on urban streets. However, feature extraction from disordered, 3D point clouds is more complex than 2D images.
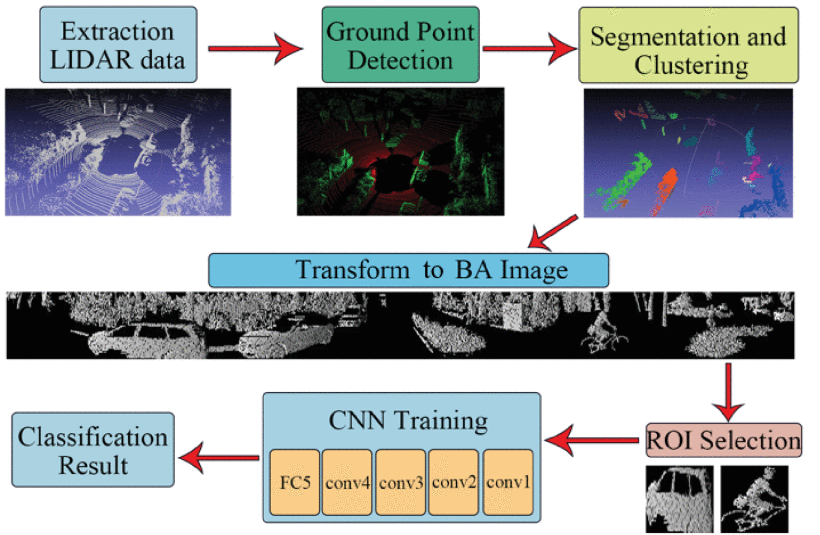
The researchers present a novel bearing angle-CNN algorithm for object detection and classification. A bearing angle (BA) image contains 2D information about the depth relationship between each point and its surroundings as well as the depth of the three-dimensional object. The proposed method involves the removal of ground points, object segmentation, transforming point cloud data into BA images, region of interest (ROI) selection, and object classification by CNN. The algorithm classifies objects into cars, pedestrians, and street clutter.
The removal of ground points reduces overall points by 40–60%, reducing the processing time and computational complexity. The individual point cloud objects are segmented and transformed into BA images. CNN uses these images as models for training and classification. Each BA image of an object has a different shape. So, a minimum bounding box called the region of interest (ROI) defining individual objects is used as input.
The proposed algorithm used an Alexnet-like CNN consisting of two convolution and pooling layers, one fully connecting and one output layer. The convolution and pooling layers extract the feature from inputted BA image. The convolution layer of CNN normalizes the BA image inputs into 16 x 64 x 64 feature maps which are further reduced by pooling layers. The fully connected layer then learns the classification from the pooled features into three classes: cars, pedestrians, and still objects.
The ablation study of the proposed algorithm mainly focuses on input format and network architecture. These studies scrutinize the elements that can increase the precision of BA-CNN. The simulation study used two different ROIs for comparison. One ROI has the target area of the BA image cropped at a fixed height and the object width. The second ROI has the object's minimum bounding box. The performance of the ROI with minimal width was better as it saved more contour features. These simulation results become input for three different CNN classifier models. The BA-CNN classifier consisting of four convolutional and pooling layers and a fully connected layer achieved maximum accuracy.
The accuracies of this algorithm, at 94.7% for pedestrians, 99.3% for cars, and 94.0% for street clutter, are better than those of contemporary state-of-the-art classification methods.
The researchers successfully showcased the advantages of using BA images as input in convolutional neural networks. The fusion of bearing angle and color images in a CNN-based classifier may produce more accurate results in the future.